 |
Instituto Superior Técnico/INESC, Portugal
Pontifícia Universidade Católica do Rio de Janeiro, Brasil
Universidad de Buenos Aires, Argentina
Universidad de Chile, Chile
Universidad de Valladolid, España
Universidad EAFIT, Colombia
Universidad Michoacana, México
Universidad Simón Bolívar, Venezuela
Universidade Estadual de Campinas, Brasil
Universidade Federal de Minas Gerais, Brasil
Universidade Federal de Pernambuco, Brasil
Universidade Federal do Rio de Janeiro, Brasil
The main goal of Project Amyri (Environment for Handling and Retrieving Information in the WWW) is to propose new algorithms and data structures for managing information to solve the inherent volumen and complexity problem of WWW, also including security, filtering and user interface issues, considering information privacy, automatic classification of information and easiness of use, respectively.
Our efforts are divided into three areas: (1) indexing, (2) interfaces, and (3) networks. These areas and their participants are described in the sections that follow.
The main objective of this area is the efficient generation of indices for very large textual databases. Partipants:
The main objective of this area is both to increase precision during the querying process and to provide easy to use graphic interfaces to information retrieval systems.Participants:
The main objective of this area is to deal with the operational and implementation aspects of distributed systems. Participants:
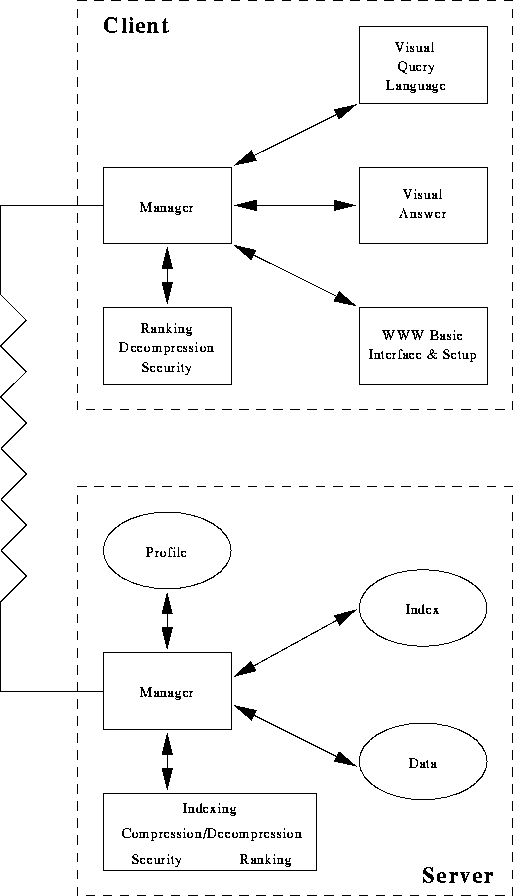
The architecture for the system Amyri is
depicted in Figure 1.
The client/server protocol is presented in Table ![]() .
.
| Client specification | Server returns |
| pattern or tag | number of docs. + list_id |
| list_id + k | list with k docs. |
| doc | vocabulary + weights |
| doc + (pattern or tag) | vocabulary + offsets collection |
| doc + atribute | doc attributes |
| doc + text | doc text |
| query + ranking method + k | ordered list of first k docs according to ranking method |
Nivio Ziviani