Chapter 1: Introduction

Contents
|
Modern Information Retrieval Chapter 1: Introduction |
Contents |
The effective retrieval of relevant information is directly affected both by the user task and by the logical view of the documents adopted by the retrieval system, as we now discuss.
Consider now a user who has an interest which is either poorly
defined or which is inherently broad. For instance, the
user might be interested in documents about car racing in general.
In this situation, the user might use an interactive interface to
simply look around in the
collection for documents related to car racing. For instance, he might
find interesting documents about Formula 1 racing, about car
manufacturers, or about the `24 Hours of Le Mans.' Furthermore,
while reading about the `24 Hours of Le Mans', he might
turn his attention to a document which provides directions
to Le Mans and, from there, to documents which cover
tourism in France. In this situation, we say that the user
is browsing the documents in the
collection, not searching. It is still a process of
retrieving information, but one whose main objectives are
not clearly defined in the beginning and whose purpose
might change during the interaction with the
system.
In this book, we make a clear distinction between the different tasks the user of the retrieval system might be engaged in. His task might be of two distinct types: information or data retrieval and browsing. Classic information retrieval systems normally allow information or data retrieval. Hypertext systems are usually tuned for providing quick browsing. Modern digital library and Web interfaces might attempt to combine these tasks to provide improved retrieval capabilities. However, combination of retrieval and browsing is not yet a well established approach and is not the dominant paradigm.
Figure ![[*]](cross_ref_motif.gif) illustrates the interaction of the user
through the different tasks we identify.
Information and data retrieval are usually provided by most modern
information retrieval systems (such as Web interfaces). Further, such
systems
might also provide some (still limited) form of browsing. While
combining information and data retrieval with browsing is not yet a common
practice, it might become so in the future.
illustrates the interaction of the user
through the different tasks we identify.
Information and data retrieval are usually provided by most modern
information retrieval systems (such as Web interfaces). Further, such
systems
might also provide some (still limited) form of browsing. While
combining information and data retrieval with browsing is not yet a common
practice, it might become so in the future.
Both retrieval and browsing are, in the language of the World Wide Web, `pulling' actions. That is, the user requests the information in an interactive manner. An alternative is to do retrieval in an automatic and permanent fashion using software agents which push the information towards the user. For instance, information useful to a user could be extracted periodically from a news service. In this case, we say that the IR system is executing a particular retrieval task which consists of filtering relevant information for later inspection by the user. We briefly discuss filtering in Chapter 2.
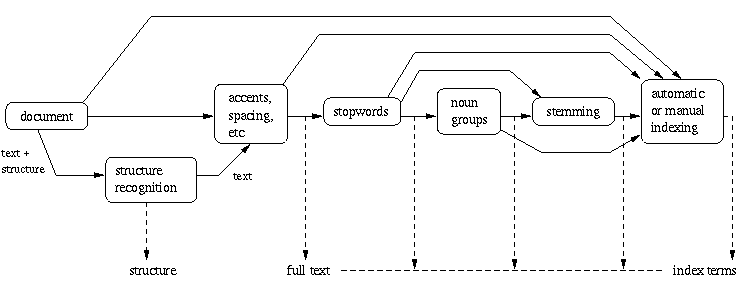
Modern computers are making it possible to represent a document by its full set of words. In this case, we say that the retrieval system adopts a full text logical view (or representation) of the documents. With very large collections, however, even modern computers might have to reduce the set of representative keywords. This can be accomplished through the elimination of stopwords (such as articles and connectives), the use of stemming (which reduces distinct words to their common grammatical root), and the identification of noun groups (which eliminates adjectives, adverbs, and verbs). Further, compression might be employed. These operations are called text operations (or transformations) and are covered in detail in Chapter 7. Text operations reduce the complexity of the document representation and allow moving the logical view from that of a full text to that of a set of index terms .
The full text is clearly the most complete logical view of a document
but its usage usually implies higher computational costs. A small
set of categories (generated by a human specialist) provides
the most concise logical view of a document but its usage might lead
to retrieval of poor quality.
Several intermediate logical views
(of a document) might be adopted by an information retrieval system
as illustrated in Figure . Besides adopting
any of the intermediate representations, the retrieval system might
also recognize the internal structure normally present in a document
(e.g., chapters, sections, subsections,
etc.). This information on the
structure of the document might be quite useful and is
required by structured text retrieval models such as
those discussed in Chapter 2.
As illustrated in Figure ,
we view the issue of logically representing a document
as a continuum in which the logical view of a document might shift (smoothly)
from a full text representation to a higher level representation
specified by a human subject.